稀疏性範例:僅擬合特徵 1 和 2#
下方繪製了擬合糖尿病資料集中特徵 1 和 2 的圖表。它說明了雖然特徵 2 在完整模型中具有較強的係數,但與僅使用特徵 1 相比,它並沒有提供我們太多關於 y 的資訊。
# Code source: Gaël Varoquaux
# Modified for documentation by Jaques Grobler
# License: BSD 3 clause
首先,我們載入糖尿病資料集。
import numpy as np
from sklearn import datasets
X, y = datasets.load_diabetes(return_X_y=True)
indices = (0, 1)
X_train = X[:-20, indices]
X_test = X[-20:, indices]
y_train = y[:-20]
y_test = y[-20:]
接下來,我們擬合一個線性迴歸模型。
from sklearn import linear_model
ols = linear_model.LinearRegression()
_ = ols.fit(X_train, y_train)
最後,我們從三個不同的視角繪製圖表。
import matplotlib.pyplot as plt
# unused but required import for doing 3d projections with matplotlib < 3.2
import mpl_toolkits.mplot3d # noqa: F401
def plot_figs(fig_num, elev, azim, X_train, clf):
fig = plt.figure(fig_num, figsize=(4, 3))
plt.clf()
ax = fig.add_subplot(111, projection="3d", elev=elev, azim=azim)
ax.scatter(X_train[:, 0], X_train[:, 1], y_train, c="k", marker="+")
ax.plot_surface(
np.array([[-0.1, -0.1], [0.15, 0.15]]),
np.array([[-0.1, 0.15], [-0.1, 0.15]]),
clf.predict(
np.array([[-0.1, -0.1, 0.15, 0.15], [-0.1, 0.15, -0.1, 0.15]]).T
).reshape((2, 2)),
alpha=0.5,
)
ax.set_xlabel("X_1")
ax.set_ylabel("X_2")
ax.set_zlabel("Y")
ax.xaxis.set_ticklabels([])
ax.yaxis.set_ticklabels([])
ax.zaxis.set_ticklabels([])
# Generate the three different figures from different views
elev = 43.5
azim = -110
plot_figs(1, elev, azim, X_train, ols)
elev = -0.5
azim = 0
plot_figs(2, elev, azim, X_train, ols)
elev = -0.5
azim = 90
plot_figs(3, elev, azim, X_train, ols)
plt.show()
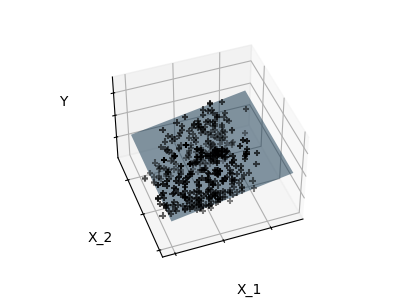
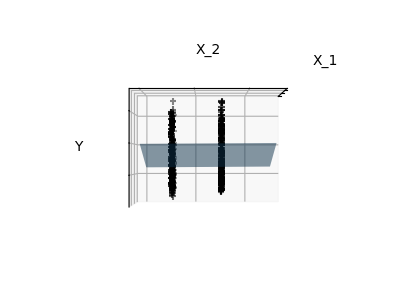
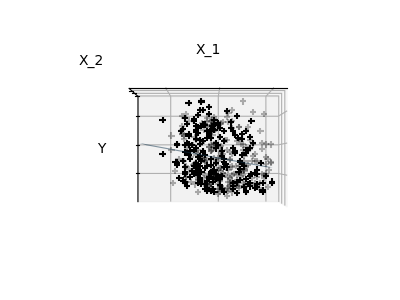
腳本總執行時間:(0 分鐘 0.198 秒)
相關範例