具有平行決策樹森林的像素重要性#
此示例顯示了如何使用決策樹森林來評估人臉數據集上圖像分類任務中像素基於雜質的重要性。像素越熱,它就越重要。
以下代碼還說明了如何在多個作業中並行化預測的構建和計算。
加載數據和模型擬合#
首先,我們載入 Olivetti 臉部資料集,並將其限制為僅包含前五個類別。然後,我們在資料集上訓練一個隨機森林,並評估基於不純度的特徵重要性。這種方法的一個缺點是它不能在單獨的測試集上評估。在本例中,我們感興趣的是表示從完整資料集中學習到的資訊。此外,我們將設定用於任務的核心數。
from sklearn.datasets import fetch_olivetti_faces
我們選擇用於執行森林模型平行擬合的核心數。-1 表示使用所有可用的核心。
n_jobs = -1
載入臉部資料集
data = fetch_olivetti_faces()
X, y = data.data, data.target
將資料集限制為 5 個類別。
mask = y < 5
X = X[mask]
y = y[mask]
將擬合隨機森林分類器以計算特徵重要性。
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=750, n_jobs=n_jobs, random_state=42)
forest.fit(X, y)
基於平均不純度減少 (MDI) 的特徵重要性#
特徵重要性由擬合屬性 feature_importances_ 提供,它們被計算為每個樹中不純度減少累積的平均值和標準差。
警告
對於**高基數**特徵(許多唯一值),基於不純度的特徵重要性可能會產生誤導。請參閱 排列特徵重要性 作為替代方案。
import time
import matplotlib.pyplot as plt
start_time = time.time()
img_shape = data.images[0].shape
importances = forest.feature_importances_
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
imp_reshaped = importances.reshape(img_shape)
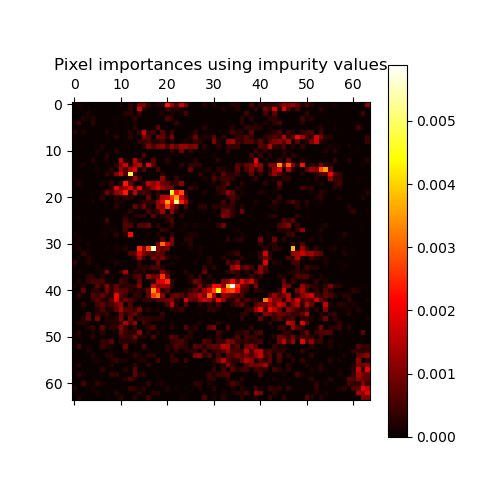
plt.matshow(imp_reshaped, cmap=plt.cm.hot)
plt.title("Pixel importances using impurity values")
plt.colorbar()
plt.show()
Elapsed time to compute the importances: 0.150 seconds
你還能認出一張臉嗎?
MDI 的限制對於此資料集來說不是問題,因為
所有特徵都是(有序的)數值的,因此不會受到基數偏差的影響
我們只對表示在訓練集上獲得的森林知識感興趣。
如果這兩個條件不滿足,建議改用 permutation_importance。
**腳本總運行時間:**(0 分鐘 1.600 秒)
相關範例